UiPath good practices
Repository and contributions here
The rationale
As software engineers, we believe it is self-evident that the success of most endeavors in the field are dependent on the practices of the team. Choosing the correct tools, the correct architecture and technological solution are important, but our day to day practices, when we don’t move mountains but rather ever so slightly advance our project, make the difference.
Automation projects have overall long feedback loops and success, or failure is measured over vast expanses of time. For this reason, it is important to have a long-term approach when it comes to implementation rather than a quick win view. This has implications for development time initially, but it pays off when it comes to debugging, maintenance, further projects using reusable pieces of code or handoff procedures
It is for these reasons that, regardless of the kind of organization undertaking the implementation, the project should be approached taking into account certain considerations:
- Scalability – easy introduction of new processes
- Ability to work in teams – both from an implementation perspective as well as the infrastructure employed
- Changing landscape (Lack of ownership of the underlying process or software) – it is usually the case that the Automation team will not have ownership of the process that is being automated or over the software/app that is being automated
- Employee turnover
- Ability to handle very complex processes without trading off stability of the implementation
Does this feel like we are preaching to the choir? These are the end goals of any organization and these goals and phrases have been used and over-used over time and space.
But we are having this conversation because over the past decade practices have emerged that have constituted the underpinnings for meteoric rises of some organizations involved in technology, companies that did not exist two decades ago and now are market leaders in their respective fields. These practices can be found under different names, but they constitute the same broad category of approaches to developing pieces of software or IT projects. Such practices are usually revolving around creating testing harnesses that fix in place solutions, automated testing frameworks, projects that are always in a state of “incomplete but ready to run” rather than “complete sub-systems and impossible to run”, continuous monitoring of systems and their constituent components and the list can go on.
Test suits are there to ensure that once a solution is found, any future changes will not impact the work completed already. Test harnesses that are run automatically ensure that adding new functionality or alterations in the work done already does not have unintended consequences. Id est, fixes for one case that break other cases if not tested properly.
While there is no book on good practices in RPA (yet), we can infer the translation of such practices.
General considerations
Design for reusability
The applications that are automated offer a wide range of functionality. Usually, processes span across multiple applications and interact with each application through a limited subset of those functionalities. Among these functionalities, from a high level perspective, we can mention:
- Initialize
- Login
- Search
- Navigate
- Check for a condition
- Add record
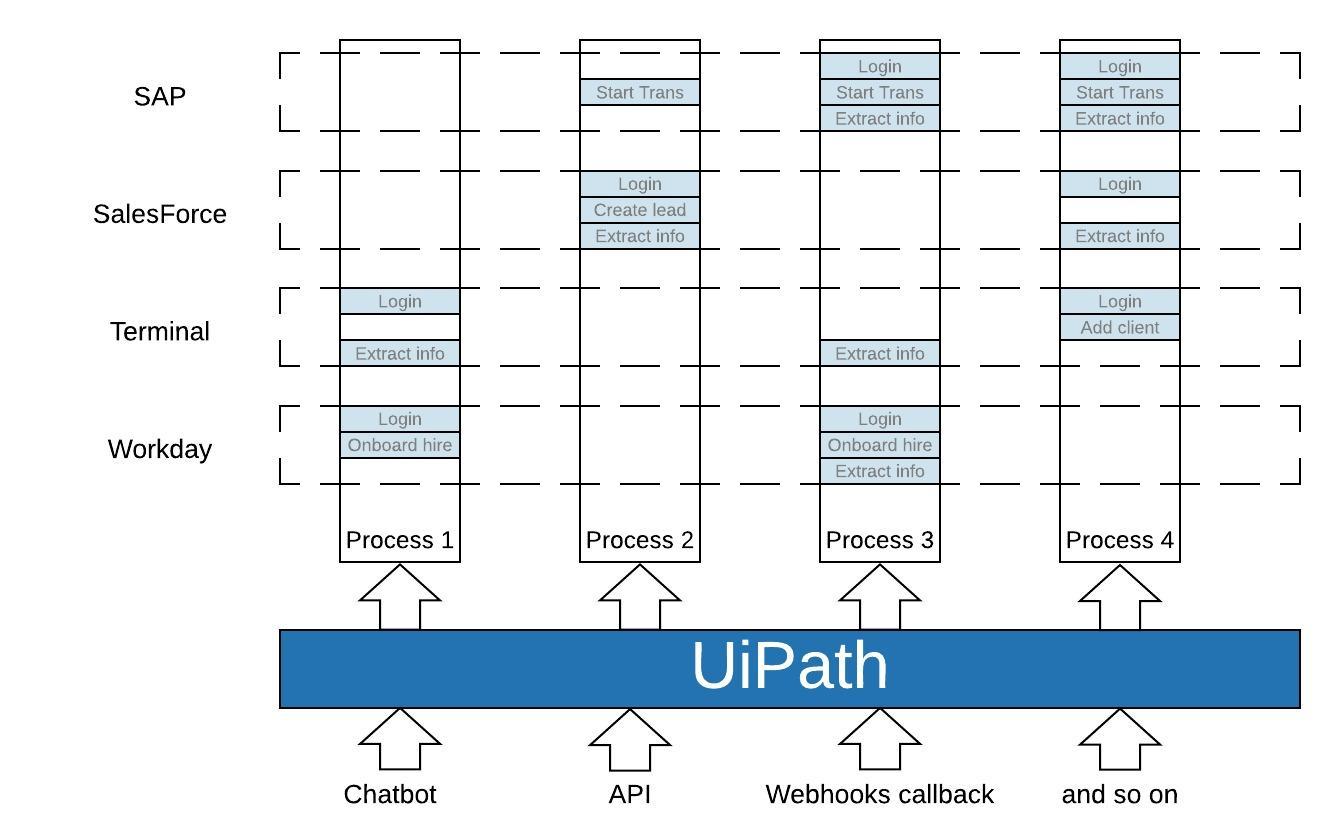
At first glance, “natural flow” of a process might be:
Initialize Application A, Login and Search for invoice #1234. From the invoice screen, Extract provider name into clipboard and switch to Application B. In this application perform Initialize, Login and Search for the provider extracted from Application A. After the provider is found, check if the invoice was paid. Switch back to Application A and Update invoice status.
A different way of viewing this process would be as a series of interactions which aggregate under the application which whom they happen.
- Application A
- Initialize
- Login
- Search for invoice
- Extract provider information from invoice
- Update invoice status
- Application B
- Initialize
- Login
- Search for provider
- Extract payment status
Design for testability
Source files should have associated test files, following some naming convention. For example, an init-and-login.xaml should have a corresponding test_init-and-login.xaml. A good folder structure to use would look like this:
some-process
│ README.md
│ main.xaml
| run-all-tests.xaml
└── app-one
│ └── tests (UnitTests and static assets used for tests)
| | └── assets
| | | | static files used for testing selectors and functionality
| | | test_nav.xaml
│ │ | test_init-and-login.xaml
| | | ...
│ └── src (the actual libray implementation)
│ | nav.xaml
| | init-and-login.xaml
| | ...
└── app-two
│ └── tests
| | | test_nav.xaml
│ │ | test_init-and-login.xaml
| | | ...
│ └── src
│ | nav.xaml
| | init-and-login.xaml
| | ...
└── Framework (REFramework and other helper workflows)
| └── src
| | │ GetAppCredentials.xaml
| | │ ReadCsvAsDict.xaml
| └── tests
| │ Test_ReadCsvAsDict.xaml
Continuously testing workflows during development will increase delivery velocity. It would be advisable to test specific operations individually, rather than as part of a longer process. In this sense, we would want to test some add record functionality once we are already in the desired window, rather than as part of a longer sequence comprising:
login -> navigate -> search -> open records form -> add record
This would help with:
- Better indentifying the workflow which fails
- Atomic operations allow for quicker turnaround times. A long sequence, taking a considerable time before failing will hinder progress
More over, placing the sequence inside of REFramework while developing, and testing it as such, would ensure an even longer feedback loop. REFramework can be quite heavy during the initialization, ensuring connectivity, getting credentials, communicating with Orchestrator. We would prefer to have the results of the execution of the workflow in seconds rather than minutes.
Implemented consistently, a large series of tests ensuring proper functionality will aggregate into a run-all-tests.xaml workflow, which can be executed before commit code to the source control repository.
Testing underlying applications
By their nature, most workflows will be stateful. They rely that the application being automated is in a specific state, on a specific page or screen, with certain controls present or activated or disactivated. Also, it is obvious that some of the interactions between the automation and the underlying application will change the state of that application. This becomes quite problematic when there is no Test environment to test in.
Tests rely on the state of the applications that are being automated, or on the state of the system. They rely on users present in the database, emails in the inbox, documents on a shared drive.
Testing strategies rely on the Fail fast and obviously principle. Failures should be caught in Dev and/or UAT, not in production. A major fallacy exhibited is the belief that applications have deterministic behaviors. There are innumerable applications which behave inconsistently, with controls that move, popups that appear and disappear without predictability. When dealing with such applications, tests should be performed in loops of tens or hundreds of iterations, for the workflows that are likely to fail. This kind of testing strategy will identify outliers and edge cases.
While automated tests strive to isolate workflows, it is usually the case that more than one functionality is tested. It is not possible to test a hypothetical Search function without testing both Initialize application and Close application. So, there seems to be an incremental approach to testing, with more “advanced” tests relying on the good implementation of more “basic” workflows.
The checklist
Inside the workflow
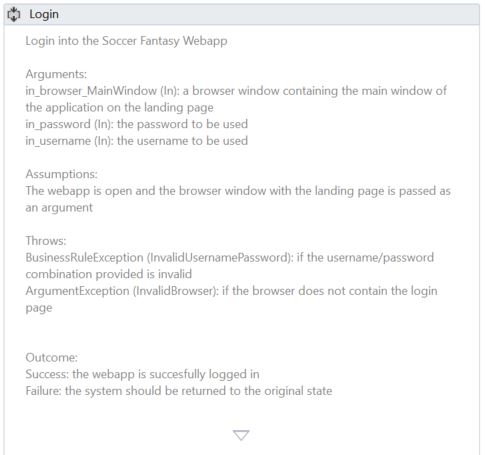
- The workflows should contain, at the minimum, an initial comments/annotations section with:
- General purpose of workflow
- Arguments (both in and out)
- Assumptions: usually regarding the state of the application being automated (what is the current page/screen, what is the current page of the terminal session and so on)
- Throws: the list of exceptions that the workflow throws and what is their significance
- Output: the state of the system/application/screen/page after the workflow is invoked ``` Extract the information from an incoming .xlsx file containing a predefined template, filled in by the originator
Assumptions: The file is accessible and the format is the expected one
Arguments: in_strFilePath (In): String containing the file path out_dictData (out): IDictionary <String, String> containing the extacted data from the file in_sstrPassword (In): Secure String containing the file password
Throws: ArgumentException(InvalidFileFormat): if the excel file is in an unrecognized format ArgumentException(FileNotFound): if the file is not in the expected location ArgumentException(InvalidPassword): if the supplied password is not correct
Outcome: Success: the data is presented in the output argument Failure: Throw ```
-
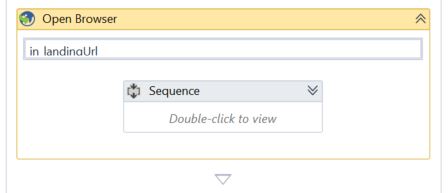
Windows, browsers, terminal sessions should be opened/found only once and then passed as arguments to invoked workflows, rather than attach the window at the beginning of workflows. This minimizes the risk of inadvertently attaching a wrong window, especially if there is a possibility of having more than one window of the same process open at the same time
-
Opening a browser:
-
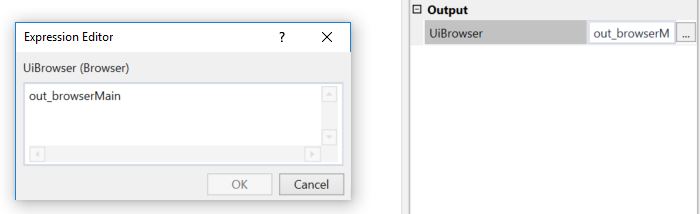
Capturing the browser as an object
-
Using the object as a reference to the opened browser in subsequent workflows
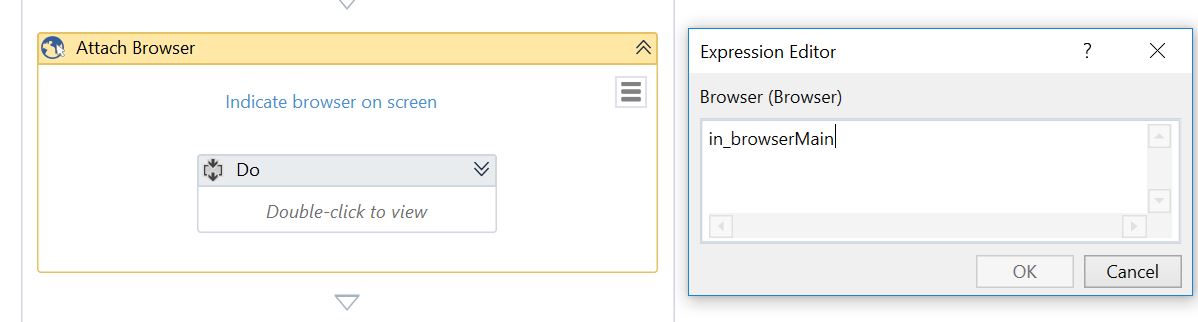
-
-
Workflows should be atomic in their intended functionality and small enough to express their complete functionality in one sentence or two. If this is not the case, seams should be searched so that the workflow can be further broken up into sub components.
Do’s:
- init-and-login.xaml
- nav.xaml (with a navigation target parameter)
- add-record.xaml
Dont’s:
- handle-new-invoice.xaml
- navigate-and-scrape.xaml
-
Workflows that are more complex should be broken up into reusable pieces of code. These complex workflows should strive to leave the overall system in the exact state it was before execution (windows that are open, pages or screens in apps). The state is referring exclusively to the presentation layer, not about data persistence which can obviously be changed.
For example, rather than implementing the whole process in one file, the individual interactions will be placed in different files and just invoked from the main implementation xaml. So, the overarching process will just be a series of imvokations of the atomic xaml files:
search-for-member.xaml | open-member-page.xaml | extract-member-info.xaml | nav.xaml (with target=home page) - When considering the seams along which the process will be divided, consideration should be paid to the likelyhood of reuse. Libraries will be preferred over processes, if other implementations will be likely to follow.
- Because of the stateful nature of workflows, calls between different libraries should be avoided. There should be a very shallow depth of the chain of calls. That is, given a folder structure like this:
some-process │ main.xaml └── app-one │ └── src (the actual libray implementation) │ | search-user.xaml | | update-profile.xaml | | ... └── app-two │ └── src │ | nav.xaml | | get-member-data.xaml | | ...there should be no calls from
app-one\src\update-profile.xamltoapp-two\src\get-member-data.xaml. All of data transfer from different applications should be handled by the overall process implementation file, such asmain.xaml. - Except for very simple workflows, IDictionary should be preferred when passing arguments between workflows. The equivalent of an unknown number of arguments until runtime confers flexibility and easier maintenance. Also, it provides for the ability to have the equivalence to “Interfaces”, when different workflows have the same argument “signature” and allow the same invocation (for example in a ForEach loop). Data should be homogeneous in those key-value mappings.
- The number of arguments for workflows should be limited to no more than 6. If more are needed, two strategies can be employed:
- the workflow should be broken into multiple workflows
- arguments should be aggregated into collections/dictionaries
- Similarily to 8., the number of variables should be restricted to a reasonable value. There is clear evidence that more than 8 variables is difficult to manage at the same time.
Passing arguments
Testing strategies
- Test existence and responsiveness of selectors
- Can be considered a smoke test
- Usually used in instances where data is input in some tabular format and most/all selectors bear large similarities
- Checks would be performed in 3 steps:
- Check existence of field
- type into/check box/select from drop-down
- verify that the interaction was successful and data was input into the field
- Test Functionality of library workflows
- Test end to end processes
Outside the workflow
- Workflows should be grouped by the underlying application they automate
- Workflows should have meaningful names that convey the exact message of what is their purpose.
- If workflows are created for later use as libraries, they should not duplicate information. Names such as test_1 should be used exclusively for dev purposes and removed from the project as soon as they are not needed anymore.
- Folder structure should be uniform and consistent. At the very least, a basic folder structure should consist of a src (for source) and tests (for tests). Deeper folder structures under src can be used if the workflows can be grouped by logical similarities or functionality. Under tests additional folders can be used to store assets used by the testing framework
Good practices in testing
The checklist
- A two-tier architecture should be employed. On the top tier, RunAllTests should handle running all the tests in the libraries. The tests that are run should be library specific.
- RunAllTests.xaml as it is implemented at the time of the writing of this document, has these features:
- Expects a configuration file, usually a csv, which contain a list of testing workflows
- Results and summaries are output in a log file as well as an output csv file
- Runs all tests in the provided file, using an invoke workflow convention regarding runtime arguments. This is as close as we can come to implementing the concept of "Interface": multiple workflows adhering to the same calling convention, but with different implementations
- Individual library tests:
- Should conform to calling conventions/contracts with the RunAllTests workflow
- Arguments should adhere to the expected input and outputs as: 1. in_LogFile (string) containing the path to the log output file 2. out_TestsResults (datatable) containing 3 columns named TestCase, Result [PASS, FAIL], Comments
- For each test, a new row should be added to the output datatable, containing the test name, result and (optionally) comments
- Test workflows, as well as implementation workflows should not be modified with changing landscape. For this reason, configuration files should be used. These files can take multiple formats: 1. Key-Value mappings, read using ReadCsvAsDict.xaml directly into a String – String dictionary. Possible uses: non-uniform tests (positive: correct_name, negative: inexistent_name), common configuration files (usernames, paths, links) 2. Lists of input values for tests for homogenous tests (the same workflow being tested for both positive and negative outcomes with multiple inputs). Possible uses: search for users (membershipNo, firstName and lastName, non-existing, multiple results for the same inputs), extract information for cases from IWD, check that the information matches